2020-02-05 TIL
할 일 목록
-
코틀린 독서
- 어제 이해 안됬던 코드 부분 그림 그려가면서 이해하기
- 코드 스피츠 코틀린 강의 정리
- 코틀린 코드 쳐보기
- 코틀린 번역 자료 보기
- 알고리즘 문제 풀기
완료하지 못한 목록
- 코틀린 코드 쳐보기
- 코틀린 번역 자료 보기
완료 목록
-
코틀린 독서
- 어제 이해 안됬던 코드 부분 그림 그려가면서 이해하기
- 코드 스피츠 코틀린 강의 정리
- 알고리즘 문제 풀기
5Fs
1. Fact
1. 네트워크
-
인터넷의 기기와 구성
- 이더넷은 전 세계에서 폭넓게 이용되고있는 네트워크 규격이다.
- 현대 컴퓨터에 탑재되어 있는 유선 네트워크 인터페이스는 거의 100%가 이더넷이다.
- 허브/스위치를 몇 단계 접속하는 것을 cascade접속이라고 한다.
- 이더넷은 접속을 작게 분할해서 프레임이라고 부르는 형태로 만들고 이걸 전기신호나 광신호로 변환해서 통신 매체에 전송한다.
-
L2 스위치
- 일반적으로 허브, 스위치, L2스위치는 거의 동일한 의미로 사용된다.
- L2스위치는 받아들인 이더넷 프레임의 수신처 MAC주소를 알아내 그 MAC주소를 가진 컴퓨터가 접속되어 있는 포트로 이더넷 프레임을 송출한다.
- 위와 같이 할 수 있는 이유는 포트와 MAC주소의 대응 여부를 MAC주소 테이블에 기록하고 있기 때문이다.
- 등록되지 않은 컴퓨터 앞으로 이더넷 프레임을 보내는 경우 L2 스위치는 프레임이 도달한 포트 이외의 포트 전체에 그 프레임을 송출한다. 이 동작을 플러딩(flooding)이라고 한다.
- 플러딩을 한 후 이걸 수신한 컴퓨터가 어떤 형태의 송신을 하기 위해 이더넷 프레임을 L2스위치로 송출하면 여기에 포함된 송신처 MAC주소와 포트 번호가 MAC 주소 테이블에 등록된다.
- L3 스위치는 그 이름대로 레이어3, 즉 IP 패킷을 처리하는 스위치다. 라우터와 L3 스위치는 기본적으로 동일한 기능을 갖는다고 봐도 무방하다.
- L4 스위치는 즉 TCP 나 UDP에서 패킷을 할당하는 기능을 가지며 부하 분산 등의 목적을 갖는다.
- L3 스위치는 LAN 를 많이 갖고 있어 단말기가 많이 설치된 네트워크의 말단에 가까운 영역에서도 이용하기 쉽다는 특징을 갖지만 L3 스위치에 문제가 생기면 라우터 기능과 스위치 기능 양쪽 다 못쓰게 된다.
-
무선 LAN
- 무선 LAN은 LAN 케이블 대신 무선을 사용해서 네트워크에 접속하는 기술이다.
- 무선 LAN은 유선 LAN보다 보안이 약하다.
- 본래 무선 LAN 그 자체는 유선 접속을 무선으로 치환해서 허브/스위치에서의 접속과 동일한 기능(브릿지)을 제공하는 것이다.
-
포트 기반 VLAN과 태그 기반 VLAN
- 물리적으로는 한 개의 네트워크를 논리적으로 여러 개의 네트워크로 분할하는 기술을 VLAN(virtual LAN)이라고 한다.
- 포트 기반 LAN은 스위치나 라우터에 탑재되어 있는 포트를 그룹 몇개로 지정해서 그 그룹에 속한 포트군을 독립시켜 하나의 LAN처럼 보이게 하는 기술이다.
- 태그 기반 VLAN은 LAN 케이블 한개 내에 여러개의 LAN 정보를 흘려 보내는 기술이다. 이더넷 프레임 내에 VLAN 를 나타내는 정보(태그)를 내장함으로써 LAN 케이블 한개에 흘리는 정보를 VLAN으로 구분한다.
-
VPN이란
- VPN(virtual Private Network)은 인터넷 등 기존 네트워크 내에 새로운 가상 네트워크를 만드는 기술이다.
- VPN을 이용하는 경우 만의 하나 도청 등을 당하는 상황에서도 일정 수준의 기밀을 보장하도록 암호화를 병용한다.
- 터널 기술은 어떤 통신회선 내에 만들어낸 가상 통신 회선이다. 터널을 여러 개 만들면 통신 회선 한 개를 여러 개의 가상화 통신 회선으로 이용할 수 있게 된다.
-
가상화
- 가상화란 물리적인 네트워크나 컴퓨터를 사용해서 논리적인 네트워크나 컴퓨터를 만들어 내는 기술이다.
- 가상화로 물리적인 장비 한 대 내에 여러 대의 논리적인 장비를 만들어내거나 반대로 여러 대의 물리적인 장비를 한대의 논리적인 장비로 보이게 할 수 있다.
- 가상화의 장점으로 물리적인 장비의 대수나 장소에 제약을 받지 않고 기능을 이용할 수 있다는점. 장비의 처리 능력을 효과적으로 사용할 수 있다는점. 장비 각각이 갖는 것 이상의 능력을 낼 수 있다는점 . 필요에 따라 규모 확장/축소가 쉽다는 점이 있다.
-
클라우드
- 클라우드의 특징은 이용자가 직접 web 화면 등을 통해 컴퓨터, 네트워크, 각종 서비스를 자유롭게 조합해서 필요한 시스템이나 서비스를 구성한 후 이걸 네트워크를 경유하여 이용할 수 있다는 점이다. 이 배경에는 가상화 기술이 중요한 역할을 한다.
- Iaas(Infrastructure as a Service)
- Paas(PlatForm as a Service)
- SaaS(Software as a Service)
-
웹을 지탱하는 기술
- 하이퍼텍스트에는 문서 내에 하이퍼링크라고 불리는 다른 문서에 대한 참조가 있고 하이퍼링크를 따라가면 어러 개의 문서를 연관 지어서 전체적으로 거대한 정보를 나타낼 수 있다.
- URL : Web에 존재하는 문서나 각종 파일의 위치를 표시하는데 사용됨
- URL은 크게 나눠 scheme, host, path 세부분으로 나뉜다.
-
정적 컨텐츠는 미리 제작해서 서버에 보존되어 있는 컨텐츠이다.
- 항상 동일하도록 유지되면 좋은것에 사용된다.
-
동적 컨텐츠는 읽기 요청할 때마다 프로그램이 동작해서 만들어내는 커텐츠이다.
- 접속할 때마다 결과가 바뀔 가능성이 있는 것에 사용한다.
-
HTTP
- HTTP(HypertextTransfer Protocol)는 web서버와 web클라이언트 간에 web 정보를 주고받기 위한 프로토콜이다.
-
이전에 무엇을 요청했는가에 따라 응답이 변하는 일이 없이 동일한 조건이라면 요청에 대해서든 응답이 상항 동일하다고 나오는데 사실 method에 따라 다르다. post는 다를 수 있음.
- 서버의 정보가 안전한 것은 head와 get이다.
- 멱등성을 가지는 메서드는 get delete put head 등이 있다.
- HTTP 요청을 TCP/IP로 서버에 보내면 서버는 이걸 받아서 요청 내용을 처리하고 그 결과를 HTTP dmdekqdmfh qhsosek.
- 요청에는 요청 대상, 헤더필드, 메시지 본체의 각 부분이 있으며 하고자 하는 조작 요청을 대상 메서드로 지정한다.
- 응답에는 상태값, 헤더 필드, 메시지 본체의 각 부분이 있으며 처리 결과는 상태코드로 표시된다.
-
HTTPS와 SSL/TLS
- HTTPS는 HTTP통신에서의 통신을 안전하게 보호하기 위한 구조다.
- 포트번호 443이 할당되어져 있다.
- HTTPS는 SSL(Secure Sockets Layer)/TLS(Transport Layer Security)라고 불리는 프로토콜이 만들어내는 안전한 연결 방법을 사용하고 이를 기반으로 HTTP에 따른 통신을 한다.
- HTTP의 요청이나 응답 내용은 암호화 되고 도중에 누가 통신내용을 변경했는지 검사할 수 있고 접속한 WEB서버가 진짜인지 검증할 수 있다.
-
이외의 어플리케이션 계층 프로토콜
- STMP : 전자 메일 전송에 사용되는 프로토콜이다.
-
POP3와 IMAP4는 메일함을 읽는 프로토콜이다.
- POP3는 메일 함의 메일을 PC에 넣고 PC내에서 정리나 열람을 하는 형태
- IMAP4는 메일을 서버상의 메일함에 둔 상태에서 정리나 열람을 하는 형태
-
FTP 파일을 전송하기 위한 프로토콜
- 전송 제어를 위해 21, 20 포트를 사용
- 한개는 실제 데이터를 전송하는 것 나머지 하나는 제어하기 위한 접속은 독립되어 있으므로 전송 도중 중지시키는 등의 컨트롤을 하기 쉬워짐
-
액티브 모드와 패시브 모드
- 액티브 모드는 아무것도 지정하지 않고 FTP 프로토콜에서는 FTP 서버가 클라이언트에게 연결 하려고 하는데 가정이나 사무실 네트워크는 외부에서 부정 침입을 막기 위해 외부에서 내부로의 접속을 금지한다.
- 액티브 모드의 문제점을 해결하기 위해 FTP 클라이언트 측에서 두번 째 접속(전송데이터용)을 연결하는 패시브 모드가 설정된다.
-
SSH(secure shell)
- 서버나 네트워크 기기에 접속해서 대상을 CUI로 조작하는 데 사용하는 프로토콜 및 그걸 하기 위한 프로그램의 명칭이다.
- 암호화 되어 있어서 안전하게 대상을 조작할 수 있다.
-
DNS
- IP 주소 대신 컴퓨터에 부여된 명칭인 도메인명을 쓴다.
- 도메인명에서 IP주소를 찾는 것(정방향), 혹은 반대로 IP주소에서 도메인 명을 찾는것(역방향)을 이름 분석(name resolution)이라 한다.
- DNS를 구성하는 서버에는 컨텐츠서버, 캐시서버 두 종류가 있다.
-
NTP
- 네트워크에 연결된 컴퓨터의 시간을 맞추기 위한 프로토콜
- NTP로 시간 정보를 제공하는것은 NTP 서버다.
- NTP 서버는 계층적인 구조를 취한다.
-
HTTP 프락시
- 웹 서버와 직접 통신하지 않고 어떤 형태의 중계용 컴퓨터를 거쳐 인터넷과 주고 받는 형태.
- 위와 같이 사이에 두고 통신 내용을 전하는 컴퓨터를 프락시라고 한다.
- 프락시가 제공하는 기능으로 컨텐츠의 케시와 바이러스 검출 유해사이트 차단이 있다.
-
서비스 연계와 REST API
- 네트워크를 경유하여 호출해서 사용하는 서비스를 제공하는 사업자나 서비스를 ASP라고 함
- ASP 나 SaaS/PaaS 등의 기능을 네트워크를 경유해서 호출할 때 많이 사용되는 것이 HTTP이다.
- HTTP를 사용해서 네트워크 경유로 기능을 호출하거나 XML이나 JSON으로 결과를 돌려주는 형태를 일반적으로 REST API라고 함.
-
HTML의 구조와 XML
- HTML에서 사용하는 문서를 기술하는 언어이다. 태그라고 불리는 명령어를 사용해서 텍스트 파일 내에 표시하므로 마크업 언어라고도 한다.
- XML은 마크업 언어를 정의하기 위한 범용적인 규칙을 정의하여 작성 규칙이 엄격하다.
- HTTP 요청은 한 번에 한 개의 요소만 취하므로 여러 번 주고 받으며 복수개의 표시 요소를 읽어들인다.(ex 이미지)
-
문자코드
- 컴퓨터가 다룰 수 있는 데이터는 그 구조에서 수치로 제한된다.
- 수치와 문자를 대응시킨 문자 코드가 정의되어 있어 우리는 컴퓨터에서 읽거나 쓰거나의 작업을 할 수 있다.
- 통신으로 주고받을때나 컴퓨터 내에서 처리 할 땐 정보나 문자에 대응하는 수치의 집합으로 처리된다.
- 문자에 대응하는 숫자를 문자 코드라고 부른다.
2. 코틀린 코드스피츠
continuation & CPS
- continuation : 우리가 알고 있는 콜백과 부합
- CPS : continuation을 실질적으로 응용하는 방식, 콜백을 패스하는 개념
-
Continuation & Sequence
- 밑의 코드 또한 continuation을 사용한다. c에는 cont가 없으면 a로 초기화 하고, 있으면 있던것을 쓴다.
- continuation func은 return 값으로 continuation을 반환
- while문의 조건 안에서는 반복적인 일 (밑의 코드의 주석으로 실행으로 표시한 부분) 이 이터레이션이다.
- 이터레이션으로 보면 while의 조건이 hasNext continuation(3,cont)가 next 부분임. 그러므로 이런 continuation의 행동은 이터레이션에 수련하게됨.
- continuation을 쓰고 있는 코드의 분할을 자동으로 만들어 주는 것이 코틀린에서 고유명사 sequence이다. continuation 구문을 자동으로 만들어주는 이터레이션 생성기이다.
class Cont<T> {
var state = 0
var isCompleted = false
var result: T? = null
fun resume(v: T) {
state++
result = v
}
fun complete(v: T) {
isCompleted = true
result = v
}
}
fun continuation1(a: Int, cont: Cont<Int>? = null) = run {
var v: Int
val c = if (cont == null) {
v = a
Cont()
} else {
v = cont.result!!
cont
}
//본문
when (c.state) {
0 -> {
v++
println("state $v")
c.resume(v)
}
1 -> {
v++
println("state $v")
c.resume(v)
}
else -> {
v++
println("state $v")
c.complete(v)
}
}
c
}
fun main() {
//실행
var cont = continuation1(3)
while(!cont.isCompleted){
cont = continuation1(3, cont)
}
println(cont.result)
}-
이렇게 하면 만들 수 있음.
- continuation은 코드에 없으나 지가 알아서 만들것임
- yield() 를 쓸 때마다 iteration이 나눠지는것임
- 왜 이렇게 짰는데 continuation이 생겨나는지는 컴파일러가 기능을 수행하기 때문이다.
- 우리는 sync block 형태로 짜길 원한다 이게 이해하기 쉽다.
-
sequence란 block이 나오면 밑과 같이 짜면 컴파일러는 위의 코드처럼 만들어준다. 밑은 컴파일러가 하는것이다.
- continuation 객체를 만들고
- continuation 객체를 호출하는 형태로 변경
- 안의 코드도 yield를 기준으로 각각의 케이스를 다른 스테이트로 나눠서 코드를 위의 when과 같이 바꿔줌
val s = sequence {
var v = 3
v++
println('state $v")
yield(v)
v++
println('state $v")
yield(v)
v++
println('state $v")
yield(v)
v++
}
println(s.last())- 컴파일러는 sequence란 함수에 무슨 비밀이 있어서 이렇게 나눌 수 있는게 아니라 실제 sequence라는 애는 sequence context를 가지며 sequence context에 있는 메소드 yield를 호출 한것
- sequence는 수신함수(확장함수)이기 때문에 context로 sequence context를 받아 들임.
- sequence context 안의 메소드중 yield가 있기 때문에 sequence에서 사용할 수 있는것이다. 사실 this.yield임(왜 this를 생랴이 가능할까 ?)
- 밑의 코드중 가장 중요한 부분은 suspendCoroutineUninterceptedOrReturn { c-> 부분이다.
- 위의 c가 continuation이다.
- 여기서 나오는 suspend는 위의 코드에서 when에 나오는 하나의 섹션을 의미한다. 한번에 이 코드를 실행하지 않고 분할해서 나눠줘야하는 지점을 suspend라고 부름
- 위의 함수는 yield() 전까지 리턴이 된 상태임. 일반 적인 함수는 처음부터 시작해서 끝에서 끝나는데 코루틴이라는 형태의 함수들은 중간부터 중간을 리턴할 뿐만 아니라 중간부터 시작해서 중간을 리턴할수 있음 위의 코드와 같이 바뀌니까
- 각 섹션의 yield()가 일어나기 전까지의 것 하나하나를 suspend라고 한다 함수가 끝까지 실행되지 않고 멈춘다는 것임 중간 리턴 때 멈춤
- 그다음 suspend 된걸 재개하는데 이걸 resume 한다
- 밑의 코드는 nextStep을 현재의 continuation으로 리턴한 것 처럼 continuation 리턴에서 nextStep은 여기서 안보이지만 sequence context의 속성인데 얘를 다음번 continuation으로 잡아주고 리턴 값을 suspend상태로 보내주는 것이다. yield하면 suspend이니까
- 실제로 컴파일 타임에 이 코드를 나누게 되는 비밀은 suspendCoroutineUninterceptedOrReturn { c- >} 이다
- 위의 것이 컴파일러가 직접 코드를 나누게 명령내리는 컴파일러 전용 명령이다.
- 위의 것이 각각 continuation state로 나뉘어 지는 것이다. continuation state 1,2,3로나뉘어 지는 이유가 suspendCoroutineUninterceptedOrReturn얘임
- 위의 것은 suspendCoroutine 로 부터 파생 되는데 내용을 보면 구현이 internal로 되있음 언어에 맞춰 시스템이 구현 한것이고 개발자가 할게 아님 컴파일러가 처리할 것임. suspendCoroutineUninterceptedOrReturn 지점을 기준으로 분해시키라고 컴파일러에게 명령을 내리는 것임 이곳이 suspend pointer라고 yield가 나올때 마다 컴파일러에게 시켜서 suspend pointer 마다 분해를 시키는것 그때마다 분할 하자마자 continuation이 생겨나는 것임 왜 continuation을 인자로 받는지는 시스템이 날라주고 시스템이 continuation을 만들기 때문.
- 아까 위의 코드에선 우리가 만들었음. 이건 컴파일러가 continuation을 만드니까 컴파일러에게 받는것임.
- sequence는 실행은 하지 않는다. 직접 하나하나 실행 해줘야한다.
suspend fun <T> suspendCoroutineUninterceptedOrReturn(block: (Continuation<T>) -> Any?): T //Continuation<T> 얘가 바로 코루틴내장되어져 있는 continuation 객체이다override suspend fun yield(value: T) {
nextValue = value
state = State_Ready
return suspendCoroutineUninterceptedOrReturn { c ->
nextStep = c
CORUTINE_SUSPENDED}
}- CO : 일반적으로 코루틴 시스템이 적용되는 많은곳에서 수동으로 실행함수를 만들때 쓰는 기법
- 자바스크립트의 generator는 sequence와 똑같은 기능을 함. yield를 호출할 때마다 suspend 구간이 생기고 거기에 continuation을 만들지만 es6에서는 continuation의 제어권을 직접 주진 않음.
- 하지만 코루틴시스템에선 continuation 제어권을 인터페이스가 준다.
- 제너레이터에서는 yield를 원하는 타이밍에 할 수 없음. 왜냐면 동기 로직 안에서 yield넣을수 있을 뿐 이 안에서 ajax callback에 yield를 하는건 불가능. 동기화 로직 yield밖에 안된다. 왜냐면 우리가 yield 할 때 continuation을 제어권 없이 yield 하는 타이밍에 continuation이 resume이 되기 때문이다.
- es8에서는 sync/await과 제너레이터를 결합해서 yield 타이밍을 미룰 수 있는 async generator가 있음 걔를 이용하면 sequence와 동등한 스펙을 구현할 수 있음.
- 제너레이터 안에서는 조종할 수 없지만 밖에서 제너레이터를 이터레이션을 돌리는 코드를 원하는 타이밍에 이터레이션 될 수 있도록 하는것이 코루틴의 CO의 원리이다.
- 제너레이터 또는 코루틴의 구현체가 단방향인 경우 코루틴 안에서 밖으로 이터레이션 값을 줄 수 있지만, 밖에서 코루틴 안으로 이터레이션 값을 줄수는 없다.
- es6 제너레이터는 yield도 받고 next에 괄호 열고 값을 넣어줄 수도 있음. 그러면 코루틴에서는 못쓰는 a = yield(30) 이런 값을 받을 수 있음. 양방향 통신을 함. 밖에서 제너레이터 안으로 yield로 인자를 여러번 보낼 수 있음.
- yield 상태에선 통신이 안되기 때문에 최초 함수의 인자는 받을 수 있지만 안에 있는 코루틴 이터레이션에서는 중간에 인자를 받을 수 없다.
class State{
var result = ""
lateinit var target:Promise<Response> // 현재는 null
}
sequence{
val s = State() //최초의 스테이트 탄생 시킴
s.target = window.fetch(Request("a.txt")) //window.fetch는 promise<Response>를 리턴하는 promise
yield(s) //yield로 state 객체 자체를 보냈음.
s.target = window.fetch(Request(s.result)) //얘는 외부의 인자를 받아왔을 것임. 이것을 통해 외부와 대화를 할 수 있게 됬음. s객체의 result만 갱신하는 걸로 코루틴 안에서 밖깥쪽의 값을 얻어올 수 있음.
yield(s)
println(s.result)
}
fun co(it:Iterrator<State>? = null, seq: SequenceScope<State>? = null){ //sequenceScope의 타입이 state인 이유는 밑의 yield에서 s(State)를 보내기 때문에 타입 확정
val iter = it ? :seq?.iterator() ?: throw Throwable("invalid)
if(iter.hasNext() iter.next().let {st ->
st.target.then{it.next()}.next{
st.result = it
co(iter)
}})
}
//첫번쨰 인자는 없으면 알아서 null 처리 함
co(sequence{
val s = State()
s.target = window.fetch(Request("a.txt")) //window.fetch는 promise를 리턴함. a.txt를 날릴 껀데 여기 까지가 promise<Response>를 주는 promise이다
yield(s)
s.target = window.fetch(Request(s.result)) //코루틴 안쪽에서 밖의 값을 얻어올 수 있음. 이런 방식으로
yield(s)
println(s.result)
}) - 위의 코드에서 중간에 대화를 할 수 있게끔 하기 위해 기본적인 target을 Promise<Response>로 지정
- 양방향 통신이 안되는 코루틴 같은 시스템에서는 직접 양방향 통신을 위한 메모리 공간을 갖고 있는객체를 외부에 출력해 줘야지만 그 객체의 속성을 안에서 이용할 수 있음.
- 그래서 yield로 부터 리턴값을 받아온건 아니지만 s의 속성으로 받아올 수 있음.
- 하지만 위까지는 안쪽 사정이고 우리는 시퀀스를 이용하는 CO 함수를 만들고 싶은것이다.
- 막 점프하고 하는게 너무 복잡하고 그러니 간단하게 sync block방식으로 사용하게 끔 co가 나온것
- co 코드의 SequenceScope<State> 가 sequence함수의 리턴값 왜 State냐면 yield 할떄 입력값이 State() 이기 때문.
- co 코드의 iterator는 contination의 passing에 의해 iterator가 직접 있는 경우와 없으면 seq?.iterator()로 받아오고 있음. 근데 둘다 안줬으면 Throw를 날림
- seq는 iteration을 return 함
- iter.next()는 State 객체가 나옴 . 위의 seq 스테이트 객체를 반환하는 iteration을 갖고 있는 seq 이기 때문이다.
- State는 Promise<Response>임.
suspend & coroutine
- cps와 suspend 와 코루틴을 이용하여 섹션을 만들어 내서 continuation을 자동으로 만들어줄 수 있다라는 기본 개념을 알게 되었고,
- 이전까지완 지금부터는 다른데 위에서 배운 기저 시스템을 이용해서 async generator처럼 비동기로 실행되지만 section 구분을 자동으로 컴파일러에게 의뢰해서 구문들을 만들어내는 일종의 닉네임들과 여러가지 니모닉으로 이루어져 있는 시스템을 제안함
- 결국 여기나오는 것들은 sequence와 continuos resume으로 다 번역이 됨 하지만 이것 깊숙히 감쳐줘 있고 이걸 추상화 하여 추상화한 객체끼리 통신들을 그 위에층에 만든것임 결국 위에층이 밑에 층에 깔린걸로 바뀜
- 위에서는 아얘 다른 언어로 만들어 놨음.(DSL)이걸 이해하기 위해선 윗쪽의 것들을 다 이해 해야한다.
- 코틀린 코틀린 생태계에서 나오는 coroutines는 위에서 나왔던 coroutine과는 다른 애다 고유 명사임
- 서브루틴이란 반복된 로직이 있는 경우 함수안에 가둬놓고 재활용해서 호출함으로 써 재활용 하는것
- 서브루틴 특징으로 인자와 리턴값이 있어서 서브루틴 내부가 위에서 아래로 한번 실행되는게 특징 이었음. 얘는 한번 돌고 끝이남
- 코루틴은 함수의 진입접과 리턴은 있을지 몰라도 중간에 계속해서 빠져나오고 진입할 수 있는 yield라는 공간들이 있어서 함수의 처음 호출 이외에도 여러번 진입 나오기 진입 나오기를 반복할 수 있는 스타일을 코루틴이라고 부름. co(복수) routine
kotlin coroutines
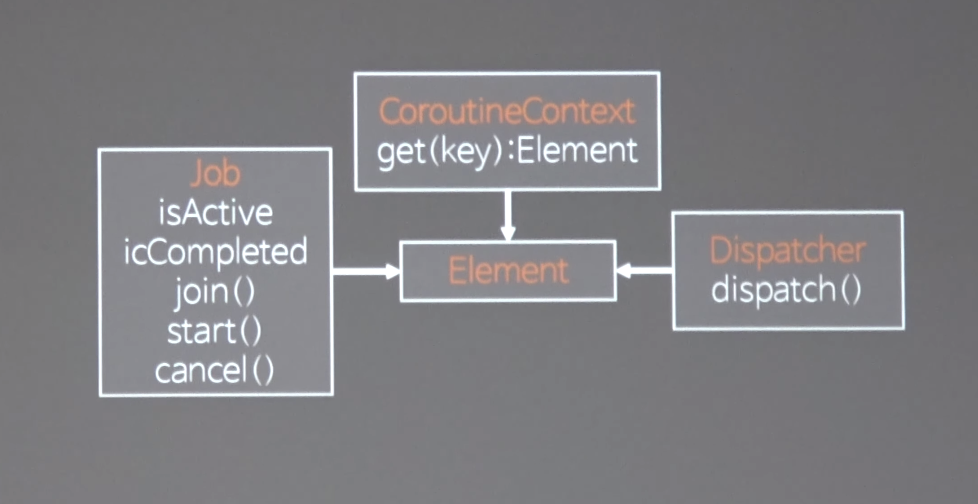
- 가장 핵심 적인 내용은 coroutineContext get(key):Element : 엘리먼트 라는 애의 컨테이너다 라고 생각하면 된다.
- 코루틴 컨텍스트가 하나 있으면 여기에 element를 잔뜩 집어넣을 수 있음. map 이랑 set 같은 놈임
- 그래서 coroutineContext element를 의존한다. 보유도 하고 있다. corutineContext -> element
- 그래서 coroutineConext == element 라고 해도 됨
- 하지만 그 coroutineContext가 element의 구상체임에 불구하고 다른점은 element의 컨테이너 이기도 하다
- element를 job과 dispatcher가 상속을 함.
- dispatch : 아까 우리가 만든 sequence가 아니라 코어 함수에 해당하는 실행기. 얘각 바로 실행해주는애. 우리가 만든애는 실행기가 아니라 sequence를 실행해줄 코어 함수가 필요 했음 .
- 코루틴 컨텍스트는 실행기인 dispatcher도 소유하고 아까 sequence까 만들어준 iteration 객체 하나하나가 job이다
- 코루틴 컨텍스트는 시퀀스 마냥 여러개의 이터레이션 객체들을 소유하고 그것을 실행하는 코어함수인 dispatcher를 소유하는 객체임.
- 대부분의 코루틴컨텍스트는 하나의 dispatcher와 다수의 job으로 이루어져있음.
- 서스펜드 코루틴 섹션을 만들어주는 시스템과 코어라는 이터레이션 실행기를 객체로 역활모델로 추상화 한게 코루틴 컨텍스트가 걔내들을 다 소유하는 컨테이너가 되고 이안에 실행기의 디스패처와 각각 이터레이션 나타내게 되는 잡들을 집어 넣게 되는것임.
- job은 하나의 이터레이션을 추상화했기 때문에 대략 얼추 비슷한 기능을 갖고 있는 메소드가 제공된다 아까는 switch로 나눈 구문이 무조건 실행됬는데 이 안의 메소드 호출에 따라서 실행할지 말지 대기할지 추상화를 해놓은것임 이 일이 끝난 후에 continuation의 resume을 부르는 것은 당연한대 resume 부르는 행위를 언제할지를 추상화 시켜놔서 우리에게 추상화된 개념으로 제공해줌 하나의 이터레이션에 해당하는 녀석임
- 하지만 sync 로직만 커버함
- 처음 만든 sequence는 syn 로직이었는데 두번째로 한 promise는 밖에 있는 co 실행기가 then을 통해 resume을 시켰기 때문에 비동기 적으로 구현됬음. 하지만 자바는 promise와 비슷한 completedFuture라는 추상객체가 있음.
- job을 상속해서 deferred라는 애를 만듬 얘는 then과 마찬가지로 await하는 시점에 모든 비동기가 해결 됬을때 resume을 호출해 주는 job으로 부터 상속받은 비동기를 처리하기 위한 것 promise와 비슷함
- yield를 상수값으로 할 경우 동기적으로 내보내면 되지만 promise같은 애가 개입하면 아까 co에서 promise.then을 처리한 다음에야 우리가 co를 다시 호출할 수 있었음.
- 마찬가지로 힌트를 줘야함. 이 이터레이션이 동기적인 명령인지 아니면 비동기의 완료시점에 resume을 해줘야하는지 알아야함 내부적으로 이것을 추상화하고 있는 객체가 deffered
- deferred는 then과 마찬가지고 await하는 시점에 비동기가 모두 해소됬을 때 resume을 해소해주는 promise then을 똑같이 해준것 같은 job을 상속받은 비동기를 처리하기 위한 객체임
- 동기적인 iteration은 다 job에 때려박고, 비동기 적인iteration은 다 deferred에 때려박음
- deferred에 때려박으면 await 시점에 resume이 일어나고 job은 바로 start가 일어나서 join될때까지 바로 실행 되는것임
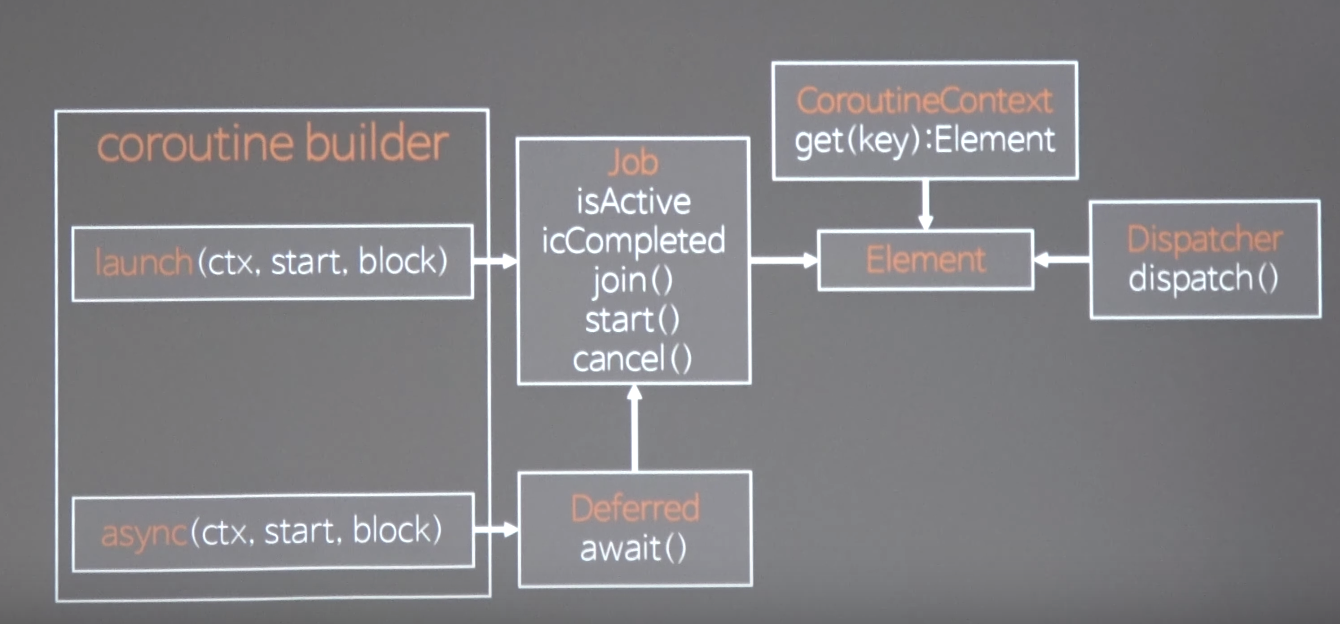
- job과 deffered는 coroutine builder라는 애로 만든다.
- launch를 이용하면 job을 만들 수 있고, async를 이용하면 deffered를 만들 수 있음.
- 둘중 하나를 만들어 coroutineContext에 빡빡 밟아주고 ..?? 실행하면 얘가 디스패처로 통해 자기가 쌓아놓은 job과 deferred를 co처럼 돌아가면서 이터레이션 실행한다.
- 그럼 job과 deffered로 만든 이 생태계를 아까처럼 switch 문으로 나눠주는 컴파일 과정이 있어야되는데 여기서 job과 deffered를 실행기인 dispatcher로 실행할 거지만 니가 내가만든 동기 코드를 job이나 deffered에 이 시점을 바탕으로 스위치 문을 다 state문으로 나눠 continuation 객체까지 다 연결해 줘야되 라는 지시를 컴파일러에게 해줘야하는데 .
- 이 동네 전체를 한꺼번에 suspend coroutine 하라는 키워드를 지정할 수 있는데 그것이 바로 suspend이다.
- 함수 앞에 suspend를 붙히면 그 함수 전체는 job 또는 deferred의 기준으로 자동으로 continuation section을 컴파일러가 만들어줌
- 우리는 cps 스타일 위에 sequence 시스템이 어떻게 움직이는지 suspend coroutine 함수가 시스템에 어떤 영향을 끼치는지 그 시스템을 추상화 해서 어떠한 구조로 만들어서 언어가 그위에 구축되어져 있는지 배움
- 밑의 코드는 지금까지의 지식을 바탕으로 아까 sequence가 만들어내던 yield 함수가 suspend coroutine을 쓰는걸 직접 써보자는 것임 직접 우리가 yield함수를 흉내내서
- 밑의 함수는 컴파일러에게 명령을 내리는 함수이다. 얘가 등장하는 순간 continuation switch section을 나눠줌 suspendCoroutine은 인자로 continuation을 받음 컴파일러가 만들어준 continuation을 받을 수가 있음. 이 섹션을 더이상 진행할지 말지는 cont.resume으로 결정한다. resume일때 값을 리턴한다. block은 T를 넘길수 있는 함수를 인자로 받는 함수이다. 그렇기 때문에 밑의 코드에 블록 안에 있는 cont.resume(it)는 T를 넘길 수 있는 함수이다.
- suspend 함수는 컴파일러가 이 전체를 suspendCoroutine이나 suspendCoroutine을 추상화 하고 있는 job 또는 deferred를 기준으로 switch를 나눠줌
suspsend fun <T>task:(block:((T)->Unit)->Unit):T = suspsnedCoroutine{
con:Continuation<T>->block{cont.resume(it)} //얘가 b가 됨
}
suspend fun main(){
println("a")
println(task{it("b")}) // ((T->Unit)->Unit 여기의 it은 (T->Unit)에 해당
println("c")
}
2.Feelings
- 오늘 알고리즘 문제를 푸는데 못풀어서 기분이 정말 안 좋다. 매일 수련을 꾸준히 해야겠다.
- 기분이 안좋더라도 마인드 컨트롤을 잘 해야겠다.
- 오늘 공부한걸 정리 할 때 너무 피곤해서 그냥 따라서 치기만 하는것 같은데 다 치고 자기전에 읽어봐야겠다.
3.Findings
- 매일 수련하지 않으면 실력은 향상되지 않는다.
- 매일 꾸준히 하는게 중요하다.
- coroutine과 코틀린의 고유명사 coroutine이 다르다는것을 알게 되었다.
4.Future Action Plan
- 내일 코틀린 코드 다 쳐볼 수 있을까 ??..
- 코드스피츠 무조건 다 이해한다.
